





Data Undermining: The Work of Networked Art in an Age of Imperceptibility
¶ 1 Leave a comment on paragraph 1 0 To comment on SPECIFIC PARAGRAPHS, click on the speech bubble next to that paragraph.
¶ 2 Leave a comment on paragraph 2 0 The perceptible and imperceptibility
¶ 3 Leave a comment on paragraph 3 0 The more data multiplies both quantitatively and qualitatively, the more it requires something more than just visualisation. It also needs to be managed, regulated and interpreted into patterns that are comprehensible to humans. The labour of extracting pattern and order from data is rarely visualised for screen display in daily life. The management of data is undertaken by sophisticated sampling, tracking and automated techniques; both knowledge about and analysis of these are frequently sequestered to become the property of corporations and institutions. What we see as patterns, visualisations and diagrams are the perceptible end of data. To make something perceptible as a data visualisation is to make it recognisable, which is not in the least similar to perceiving a thing.
¶ 4 Leave a comment on paragraph 4 0 Drawing on the enactive and embodied understanding of perception variously at work in the writings of Alva Noë, Brian Massumi and Erin Manning, we can say that perceiving involves a making of the world (and of perception itself), as we go.[1] Perceiving draws on neuro-conceptual-affective processes that we barely see or know are there; micro-perceptions and sensations that might be felt and indeed even made by our sensory-motor systems but are nonconscious. We might go so far as to say that perceiving arises from the imperceptible, from what has not yet been understood, recognised or determined. The perceptible, on the other hand, arises after perception-action has already occurred and when a percept is correlated with or to other percepts. This correlation makes something recognisable. To recognise is to see something already seen. A pattern seen in data is an example of recognition, albeit a machine form of recognising. Rather than something being perceived, something is made perceptible. Data mining is a computational technique for creating pattern in large data sets. But it is a not simply a technical operation. It is a technique that manages data perception, by making data into the perceptible — data recurring as particular formations for us to see something in the already seen.
¶ 5 Leave a comment on paragraph 5 0 But what we do not regularly perceive in these perceptible visualisations are the processes, both conceptual and computational, that render pattern and relationships among the data. Even when data flows are not privatised or sequestered, their remixing and recombination in, for example, the web through the operations of search engines, databases, digests and feeds such as RSSs increasingly makes this manipulation of data invisible. These mounting reserves of data about data, the software used to extract and analyse these and the social and cultural techniques accompanying this growing trend results in a generalised state of data nonvisualisation. This is not to say that these techniques for aggregating and deciphering data do not use visualisation techniques. In the area of data mining particularly, visual environments can be modelled to make sense of patterns detected in sets of information. What is not usually visualised are the parameters, relations and arrangements that organise and make sense of data. These nonvisualised processes have become the imperceptible of data visualisation.
¶ 6 Leave a comment on paragraph 6 0 However, unlike what the imperceptible for human perception comprises — that is, the barely registering spectrum of chaotic microsensations that eventually result in something being perceived — the imperceptible processes of data management are highly determined via computational techniques of information analysis. This disjunction-inversion between the perceptible and the imperceptible in humans and computational machines, and between the technics of computation and dissonant directions in network cultures, has opened up as a sphere for aesthetic investigation. A number of projects such as ShiftSpace, MAICgregator, and Traceblog traverse the disjunctive synthesis of data perceptibility and questions of imperceptibility, deploying what I will refer to as data undermining techniques.
¶ 7 Leave a comment on paragraph 7 0 Collectively, these kinds of projects produce an area of art research into the management of data in contemporary networked cultures. This signals a very different idea and attitude toward both art making and toward the “art object”. Nick Knouf, who has been working on MAICgregator — a Firefox extension that aggregates and redisplays web data about the relationships between contemporary university research and its military and corporate funders (Military Academic Industrial Complex) — provides an interesting term to use when thinking through this kind of investigative aesthetics: “poetic austerity.”
¶ 8 Leave a comment on paragraph 8 0 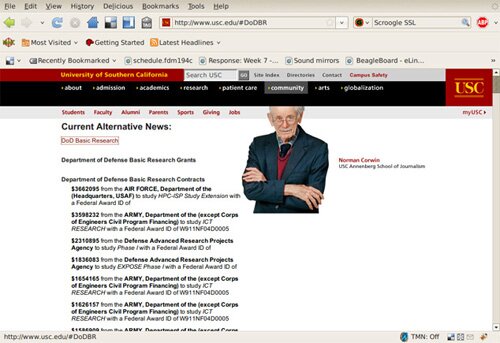
Screenshot of a MAICgregator pass on the University of Southern California’s website. Information is aggregated about the funding provided by the Department of Defense to research projects undertaken by University of Southern California researchers and redisplayed by the MAICgregator Firefox extension on the site’s web pages.[2]
¶ 9 Leave a comment on paragraph 9 0 This is a useful concatenation for unfolding the kinds of projects I will be looking at in this chapter. By “austerity” or seriousness, Knouf is referring to both the context in which art finds itself in contemporary culture — a context which is laden with the very serious and urgent issues of a knowledge economy that embeds its knowledge-producing institutions and researchers in more and more tangled relations with the imperatives of military and corporate interests. The practice of making art in networked spaces such as the Internet must take serious heed of this military-academic-industrial complex and complexity. The time for endless net.art jokes even of the extraordinary calibre of jodi.org’s work is therefore over. But, and this is what I take Knouf to be referring to when he emphasizes the “poetic” as the first term in his concatenation, we should not forget that art’s potential continues to lie with its aesthetics. The poetics of data undermining as a networked art approach lie in how extensions, aggregators and plugins use display as a mode of intervention into the spaces of existing web design. There is a poetics in the creation of networked spaces in which alternative forms of sociality might be invented and which cut across predesignated arenas for online interaction. Poetics might also unfold in the ways in which these spaces and emergent socialities conjoin toward becoming unperceptible.
¶ 10 Leave a comment on paragraph 10 0 Later in this chapter I will again take up this notion of data undermining as the unperceptible and will do so in the context of a discussion of Gilles Deleuze and Felix Guattari’s elaboration of the imperceptible (see especially Deleuze and Guattari, 1987: 308–312). For them, imperceptibility is both the plane out of which perception arises and into which it disappears again. But it is also a tactic for returning constricted forms of perception — for example, using a “pattern” discovered in data to predict future behaviour — to the multiple pluralities, variables and concatenations that constitute this plane. Data undermining, then, is the tactic of taking data toward the unperceptible in order to return a different conception of imperceptibility to networked culture.
¶ 11 Leave a comment on paragraph 11 0 Knouf’s idea of a poetic austerity connects in interesting ways with broader (re)search into what a web or net aesthetics might mean right now. In the work of, for example, artist and theorist Vito Campanelli, we encounter the idea not of divorcing aesthetics from the “seriousness” of spheres such as the economy. Instead, aesthetics must become nonideological — not governed by financial or commercial stakeholders. It must promote spaces where these interests do not dominate:
¶ 12 Leave a comment on paragraph 12 0 The only alternative to the effects of mass communication is a return to an aesthetic feeling of things, a kind of aesthetics not so much ideological, but rather more active (e.g. Adorno) — a kind of aesthetics able to bring again into society and culture feelings of economic unconcern (rather an unconcerned interest), discretion, moderation, the taste for challenge, witticism, and seduction. Aesthetics is exactly this. (Campinelli, 2007)
¶ 13 Leave a comment on paragraph 13 0 The reference to Adorno here is crucial in understanding what Campinelli really wants to unfold by this notion of unconcerned web aesthetics. What we need to grasp is the negotiation that Adorno wanted aesthetics and engaged art to undertake between the autonomy of the artwork on the one hand — that is, the preservation and ongoing engagement with its own questions of style, beauty and felt experience — and the embeddedness of art within a socio-historical context on the other hand (Adorno, 1970). Of course, for Adorno, this negotiation took the form of a dialectics, which for him ideally should lie at the core of the work of (modern) art itself. It was the art work’s ability to encompass and actively place at its heart this dialectic that gave it social import.
¶ 14 Leave a comment on paragraph 14 0 I do not think Campinelli or Knouf’s discussion of net and web aesthetics follows the continuing call for this dialectics. The crucial issue for Campinelli with respect to web aesthetics is for web design, in particular, to remain aesthetically autonomous but also not to be driven by the interests of commerce. Web + aesthetics must be forced apart. For Knouf, “poetic austerity” as I read it, is not a dialectic but rather a concatenation (see Gerald Raunig on concatenation). Net (the austere context) + art (the poetic impulse) must be forced together. What is crucial here is this question of force; force as a relational energy that pulls things away from each other or brings them into proximity. As I have suggested elsewhere, digital aesthetics demonstrates an ongoing concern with relations of proximity. Perhaps the work of networked art takes questions of proximity into its own field. This field would comprise a force field holding together (concatenating) the relationships of everything to everything else. In the section that follows this one, “A selective geneology of data mining”, I further explore this relational field by considering questions of databases, the development of data mining and the hold of topological analysis on networked knowledges and cultures.
¶ 15 Leave a comment on paragraph 15 0 Data undermining as an aesthetic strategy deals with questions of both corporate/commercial and state “concern” — this is its austerity — and attempts to connect these to a poetics or aesthetics of “unconcerned interest”. I want to explore the ways in which this mode of aesthetic investigation rides the swirling tide of ebbing and flowing data, sometimes providing a serious and austere line of sight into the increasing obsfucation of imperceptible data processes. At other times, however, data undermining is also imbricated in an expanding web of information that resides within a different realm of perception — that of the network and data machines. In other words, by deploying the very sources of data and techniques produced and developed by data mining processes, undermining data casts the aesthetic strategy into the terrain of machinic perception. Data undermining must use the very data and network structures produced by the machine it aims to seriously investigate or critique. It must try to render the data and relations produced visible, in order to poetically render perceptible the interests at stake. Hence this form of aesthetic investigation and practice negotiates a trembling set of interconnections between perception (as a realm of aesthesia always open to making and unmaking), the perceptible and imperceptibility. What data undermining must do is to remain inventive and open to the flux and flow of machine perception by finding ways to become humorous or poetic. But, at times, the work of networked art — its labour — might be to find again ways of becoming imperceptible to techniques of data management. I take up this question of becoming imperceptible at various intervals throughout this chapter, asking what becoming imperceptible might signify in an age of imperceptibility.
¶ 16 Leave a comment on paragraph 16 0 The aesthetics of data undermining is nonetheless an important aesthetico-political set of practices and directions for contemporary networked cultures, even if these practices also become caught within the relentless production of data. As much radical and thoughtful art theory and critique today suggests, the network or any other regime/institution/form of governance forces us to work with it rather than to imagine naively that we can escape its reach in an elsewhere, an outside or beyond to networked societies:
¶ 17 Leave a comment on paragraph 17 0 So the question I am trying to raise in a sense is, how does this issue of visibility relate to the production of new so-called transversal or constituent practices that cross the field and institutions of art? To what degree do regimes of legibility and the forms into which practices are constituted in order to render themselves recognisable as this or that, limit or foreclose what is possible for such new practices? And finally, what are the strategies and dynamics involved in working across situations, institutions and discourses without becoming identified with them, or subsumed to them? (Kelly, 2005)
¶ 18 Leave a comment on paragraph 18 0 As Susan Kelly — an artist who works collaboratively in the area of time-based installation but also across public lecturing and publishing — states, we need to understand the dynamics at work in transversal practices. Data mining engages the dynamics of the perceptible and imperceptible; it traverses the institutions of state, military and corporation, which have stakes in the governance of a knowledge economy; it is both situated within networked information and determines information as network. To data undermine as aesthetic strategy is to enter headlong, but at the same time knowingly, into the sticky webs and precarious voids that comprise just such interconnected topologies.
¶ 19 Leave a comment on paragraph 19 0 A selective genealogy of data mining
¶ 20 Leave a comment on paragraph 20 0 The imperceptibility of the techniques for managing data (via the growth of data mining as an arena devoted to the extraction of data and its reformulation as perceptible relationships — i.e., pattern or predictive models — is perhaps unsurprising given their genealogy. As a large and complex facet of the technics of contemporary network cultures, data mining has a number of different histories. Its techniques are intimately bound to the history of statistical analysis in the twentieth century,and the development of artificial intelligence (AI), especially boosted by rapid increases in computing power during the 1980s, and the development of machine learning, which through methods such as the application of neural nets and decision trees to data sets, conjoined statistical analysis with AI.[3]
¶ 21 Leave a comment on paragraph 21 0 These techniques and disciplines depend upon certain general computational conditions that really only became feasible for both technical and economic reasons from the 1980s onwards. Enormous quantities of data must be able to be stored — i.e., both databases as forms of media organisation and their media, initially supercomputers, but then servers, are prerequisites. Simultaneously the processing capacity to run queries, compare and analyse reserves of data so large must exist quantitatively and qualitatively. Not only, then, must CPU power increase, as it did rapidly during the 1980s, but many data mining techniques required the qualitative shift to parallel processing in order to conduct the exponential combinations involved in analyses of data that involves computing variables.
¶ 22 Leave a comment on paragraph 22 0 Importantly, it is also the relations among data, invoked in the analysis and storage of variations about a data source in relational databases, that provides the condition of possibility for data mining. For example, customers (data source) who buy a certain product (data source) defined differentially by income, age and gender (variables) are related to each other and then calculations are performed on the varying combinations between sources and variables. So we see a dynamic (qualitative) and proportional (quantitative) increase in sets of data and theory relations: “Databases are increasing in size in two ways: (1) the number N of records or objects in the database and (2) the number d of fields or attributes to an object.” (Fayaed et al, 1996: 38) Thus large amounts of data are not simply stored but rather are arranged relationally; no longer are we dealing with data as “stuff” but rather we have entered the domain of data as a topology. Topological arrangements of data produce data as a relational field, and this field becomes the “object” of analysis as well as the ground for the production of more data about data.
¶ 23 Leave a comment on paragraph 23 0 This arranging of data as relational or topological via a certain mode of databasing can also be understood as a networking of data. Here I am referring to the work of people such as in the field of network science, who understand the network via topological analysis.[4] So although some relational databases use computer networks to distribute their data to other databases or to other computer users, this is not the sense of the network I am invoking here — the inter-net/s, in other words. Rather, I am suggesting that organizing data as relational in a way that subjects it to deformations and transformations by other data or by machinic processes such as algorithms comprises the primary networked genealogy of data. I am also suggesting, then, that networking understood in this primary sense is the precondition for data mining. If data mining, “is a process that uses a variety of data analysis tools to discover patterns and relationships in data that may be used to make valid predictions” (Edelstein, 2005:1), then it is also a process whose precondition is an episteme in which information is relationally produced, arranged and conceptualized.
¶ 24 Leave a comment on paragraph 24 0 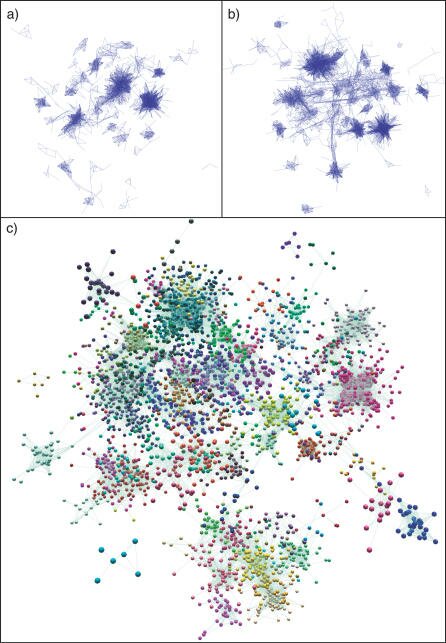
Untiled (Organic Layout) of GNF1M Network Graphs at Different Pearson Correlation Thresholds. Graphs show the mouse tissue transcription network graphs when the Pearson threshold is a set at (A) 0.98 (1,421 nodes, 69,334 edges), (B) 0.95 (2,860 nodes, 201,724 edges), and (C) 0.90 (5,410 nodes, 447,467 edges). In graphs (A) and (B), nodes have been hidden so as to show the structure of the networks, and in (C) nodes are shown and coloured according to their membership of MCL clusters (inflation value 1.5). [5]
¶ 25 Leave a comment on paragraph 25 0 The above image, for example, uses a topological visualisation of a network to arrange data about gene transcription collected from mouse tissue in a variety of different conditions. The network visualisation, then, does not represent something in the gene or even in the mouse tissue (both sources of the data collection). Instead it arranges data from sources as a visual display of the relations between the data and the differential conditions/states of the data collected. Images, techniques and arrangements such as these signal a different condition for how we think about data. Data is not information per se but rather a resource for producing knowledge as networked information.
¶ 26 Leave a comment on paragraph 26 0 In the history of computing, data mining develops out of the availability of corporate and scientific datasets, which increasingly began to be hoarded in massive reserves during the 1970s and 80s. Although large data sets certainly existed prior to this time, in particular in geographic information systems, until the 1980s the expense of both virtual and physical storage of such data meant that corporate data storage especially did not take off until that decade. It is not until the 1990s, that the term data mining sees the light of day.[6] During the 1990s, networks, AI and statistical analysis converge. Noncoincidentally, larger convergences are at work as well: the global, although uneven, growth of the neoliberal knowledge economy underpinned by, as Lazzarato has described it, the value added by immaterial labor and subtended by the technological developments of networked and multimedia communications:
¶ 27 Leave a comment on paragraph 27 0 The various activities of research, conceptualization, management of human resources, and so forth, together with all the various tertiary activities, are organized within computerized and multimedia networks. These are the terms in which we have to understand the cycle of production and the organization of labor. (1996: 138)
¶ 28 Leave a comment on paragraph 28 0 Unsurprisingly AI research, in this broader socio-economic context, thrives in the context of discovering “knowledge” (read: applying statistical techniques to data) about market-based information reserves. The work of data mining, then, does not simply lie in making something perceptible but also in using the technics of knowledge science to extract meaning from the topological structuring of data in order to add value. Wherein might this added value lie? Or, rather, how do we get to value-add, as the marketing execs might say? Here it is important to understand the second and necessarily conjunctive aspect of data mining, that it is predictive. Extracting patterns from data sets is only a worthwhile knowledge endeavour if it is going to yield some kind of potential modelling that allows for forecasting future trends or behaviour around which more sales, data and knowledge might accumulate:
¶ 29 Leave a comment on paragraph 29 0 “In marketing, the primary application is database marketing systems, which analyze customer databases to identify different customer groups and forecast their behavior” (Fayaed et. al. 1996: 38).
¶ 30 Leave a comment on paragraph 30 0 If corporations can make visible unknown patterns amid data that reveal how people behave in terms of potential future expenditure, then what future “value” might be foretold and, indeed, added back into the data sets? But, as will no doubt be gleaned from the tone of cynicism that accompanies my phrasing, the risk is large and ominous. Pattern modelling is no prediction of future behaviour. Rather it simply indicates existing relations. The slip from the perceptible into prediction is the speculative imperative residing at the core of data mining.
¶ 31 Leave a comment on paragraph 31 0 This is also where data mining gets its financial feet. At the end of the ’90s, the US military begins to get excited about data mining’s commercial applications. In a fascinating interview between the journalist Jacob Goodwin and Anthony Schaffer a US military intelligence operative working during the late 1990s, the origins of the anti-terrorist “Able Danger” operation in data mining are revealed (Goodwin, 2005). It’s worth quoting this interview at length here because it reveals the late 1990s thinking in the US military that was being driven by data mining approaches. This thinking shows the ways in which operatives such as Schaffer and operations such as “Able Danger” make the move from data analysis to prediction. That is to say, by the late 1990s the US military perceives that data mining techniques will reveal the future movements of Al Quaeda terrorists, based on data mining analysis that tracks the movement of known Al Quaeda members:
¶ 32 Leave a comment on paragraph 32 0 SHAFFER: Essentially, at the beginning of the program we didn’t know where to start. It had never been done before. To define a global target of this magnitude, which changes and adapts, was daunting. Therefore, the first stop was the Joint Warfare Analysis Center at Dahlgren [VA]. There was a conference there in the November / December timeframe of 1999, which went nowhere. Those guys did not understand the scope of trying to do neural-netting, human factor relationships and looking at linkages. They just didn’t have the capability at the time. Therefore, it was kind of a bust.
¶ 33 Leave a comment on paragraph 33 0 However, I knew from my personal experience in dealing with the Army, that LIWA, the Land Information Warfare Activity, was developing this cutting edge data mining analytical capability which I had used for other operations. So, I recommended to Captain [Scott] Philpott, “You need to go see [a person that has chosen to remain anonymous] down at LIWA and talk about what [that person] is doing.” [Capt. Philpott] goes down and gets his brief and says, “This is it. This is exactly what we’re looking for,” because they were not only using advanced data mining technology, they were also looking at data that no one else was looking at. [James] J.D Smith [a former contractor on Able Danger] talked about some of this in The New York Times [on August 22, 2005].
¶ 34 Leave a comment on paragraph 34 0 He talked about the fact that they were going to information brokers on the Internet who were getting information about the mosque system from overseas locations. Nobody else found that to be reliable. That’s why nobody was looking at it. The problem was that nobody was looking at it regarding the right type of vetting. J.D. Smith and company were using these advanced [software] tools to ferret out patterns within that information.
¶ 35 Leave a comment on paragraph 35 0 GSN: You’re talking about lists of where mosques were located geographically.
¶ 36 Leave a comment on paragraph 36 0 SHAFFER: No, individuals who were going between mosques. Who were they? Who were the contacts? Looking down to the individual level.
¶ 37 Leave a comment on paragraph 37 0 GSN: Did they say, for example, “Here’s Abdul and he’s showing up at a mosque in Pakistan and, lo and behold, he’s showing up at another mosque in the Sudan a week later”?
¶ 38 Leave a comment on paragraph 38 0 SHAFFER: Yes.
¶ 39 Leave a comment on paragraph 39 0 GSN: How did they get down to the level of who’s walking in and out of a mosque?
¶ 40 Leave a comment on paragraph 40 0 SHAFFER: Because apparently there are records of who goes where regarding visits to mosques. That was the data that LIWA was buying off the Internet from information brokers.
¶ 41 Leave a comment on paragraph 41 0 In this interview, the bones of datamining as an activity that extracts meaning via a complex set of, not only knowledge analyses, but financial transactions between the US military and commercial knowledge brokers are laid bare. In order to understand the sticky topography which networked aesthetics must negotiate, it is necessary to understand — as Knouf points us to in MAICgregator — the complex that connects together knowledge production, military interests and the commercial brokerage of data that develops in the 1990s.
¶ 42 Leave a comment on paragraph 42 0 Data, aesthetics and the web before and during the 1990s
¶ 43 Leave a comment on paragraph 43 0 Katherine Hayles has suggested that the use of computers for visualisation purposes has radically altered not only the ways in which mathematics is undertaken, but contributes toward a new kind of knowledge that is visually intuitive:
¶ 44 Leave a comment on paragraph 44 0 with computers, a new style of mathematics is possible. The operator does not need to know in advance how a mathematical function will behave when it is iterated. Rather, she can set the initial values and watch its behaviour as iteration proceeds and phase space projections are displayed on a computer screen. The resulting dynamic interaction of operator, computer display and mathematical functions is remarkably effective in developing a new kind of intuition (Hayles, 1990: 163)
¶ 45 Leave a comment on paragraph 45 0 Sherry Turkle’s early analysis of the shift to online explorations of identity through chat and text-based virtual worlds indicated that interaction with digital machines became more ubiquitous the less people knew about the technical operations of those machines (Turkle, 1995). She compared the 1984 release of the MacIntosh operating system and its relatively easy yet opaque “desktop” interface with a previous generation of “nerds” and programmers who had interacted with computers using text-based commands (Turkle, 1995: 34). The command-line interface for a previous generation of computer-human interaction encouraged its human users to tinker with the underlying code of the interface in order simply to get the machine to work. In a sense, then, the operation and performance of computational systems was more visible — although to a smaller and more elite group of people — if more cumbersome to operate.
¶ 46 Leave a comment on paragraph 46 0 There have been many debates about how graphics function in interface design, especially at the level of the Graphical User Interface (GUI). Some designers suggest that graphic representation of computational processes — the desktop as a representation of the computer’s operating system, for example — can confuse and obsfucate interaction with the computer (Norman, 1990: 216). Others have emphasised the importance of the GUI in communicating to users the complex tasks and functions that data undergoes in computation (Marcus, 1995: 425). But the use of graphics to represent both data and the processes performed upon data now definitively guides everyday interaction with computers.
¶ 47 Leave a comment on paragraph 47 0 By the late 1980s — and certainly by the introduction of GUIs for the web in 1994 — we were already less cognitively aware of the inner processing of data and its pathways through the underlying architecture of digital machines. Computers had become the exemplary black box machine – you put something in and you get something out; and most users never really understand what happens in the middle. By the late 1990s, data visualisation, especially the animation of changes to data over time, was likewise being applauded by interface designers as a technique for making computation more human-centred:
¶ 48 Leave a comment on paragraph 48 0 New ways of representing data, especially changing data, allow users to gain new insights into the behaviour of the systems they are trying to understand and make the computer an invaluable tool for understanding and discovery as well as for interpretation and mundane calculation (Dix et. al., 1998: 598)
¶ 49 Leave a comment on paragraph 49 0 During the period of the rise of computer graphics, important areas of social and economic life such as financial markets and entire disciplines, such as the life sciences, geographical systems and meteorology, were adopting and developing various kinds of data visualisation. In the development of these applications, data visualisation followed two main directions: the digital visualisation of information held previously in analog form such as printed maps, or numerical data such as statistics about climate; and the creation of information spaces such as Geographical Information Systems (GISs) — an example of the first direction – began their life in 1963 with the development of the Canadian Geographic Information Systems by Roger Tomlinson for the Canadian government’s Department of Energy, Mines and Resources. The digitisation and visualisation of geographic data has allowed query, analysis and editing of data using visual means within a visual environment. During the 1980s and 1990s, GISs were standardised across a smaller number of computer operating systems and were being accessed across the Internet. This greatly increased the ease and amount of user interaction. There are now a number of online applications that allow public access to certain kinds of GISs — map locators such as MapBlast and the virtual globe environment of Google Earth.
¶ 50 Leave a comment on paragraph 50 0 The second direction — the rendering of “pure” information spaces — includes a multitude of projects for mapping cyberspace in which complex and invisible information flows and intersections such as website traffic are visualised (see Dodge and Kitchen, 2000). An example of this kind of data visualisation can also be found in the interactive three-dimensional real time rendering of the New Stock Exchange trading floor completed by the architectural design firm Asymptote in 1999. Traders in the exchange use this virtual information environment to, for example, visually track stock performance by individual companies and graphically detect the effect of incidents on performance. Asymptote’s Lise Ann Couture and Hani Rashid state that the complexity of data interrelations in stock markets was precisely the rationale presented by the New York Stock exchange for commissioning the spatial visualisation of its information (Asymptote, 2006).
¶ 51 Leave a comment on paragraph 51 0 The fascinating paradox of all these trends toward the visualisation of data — the screen interface of the desktop computer, the dominance of GUIs in web browser design and the construction of entire information spaces as both two- and three-dimensional image-scapes — is that the structures, operations and circuits through which data move become increasingly invisible. It is often the case that during initial periods of a digital medium’s or set of technologies’ development, a period of greater accessibility to these underlying structures and processes occurs. This period of experimentation, in which technical and design protocols are less established, is often also characterised by artistic and cultural exploration of the medium/technology.
¶ 52 Leave a comment on paragraph 52 0 The first phase of web development and design from 1995 to 2001 (Web 1.0 as some now label it), required designers and artists to be versed in at least a basic level of the then broadly used scripting language for displaying information online — HTML. In other words, during this early phase of web design there were no pre-packaged methods for formatting the way a web page was displayed. All graphic and stylistic elements had to be laid out in HTML script that “told” the web browser how to format the page for online display. For a relatively short period, both artists and designers had a measure of access to the “source code” of the web and this resulted in a lot of play with HTML aesthetics. From the mid-1990s, the artistic duo of Joan Heemskerk and Dirk Paesmans, known as “jodi.org”, became infamous for their collapse of the visual levels of web display into the underlying HTML level of source code. Their home page as it appeared in 1993 and is now available at wwwwwww.jodi.org, displayed a kind of garbled screen of nonsensical green code. Those in the know about the HTML source code view available in web browsers could choose the “Page Source” option in the “View” menu and see revealed within the HTML script an embedded ASCII diagram of a hydrogen bomb.
¶ 53 Leave a comment on paragraph 53 0 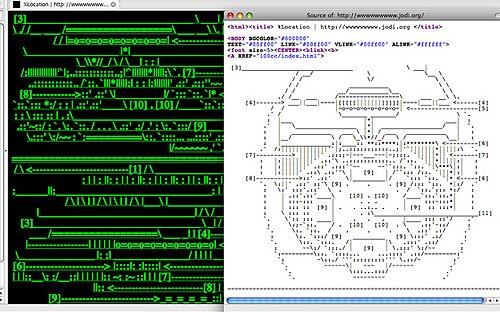
Screenshot from the website wwwwwww.jodi.org showing the “page view” and the “source view” laid over the top.
¶ 54 Leave a comment on paragraph 54 0 The implication was that the origins or “source” of scripts that allowed us to visually display networked information was in fact post-WWII military weapons research. We could say that data visualisation and data source temporarily afforded us an artificial measure of indexicality — that is, a contrived level of indexicality wrought by artifice — for networked visual culture, that insightful net artists were swift to exploit aesthetically.
¶ 55 Leave a comment on paragraph 55 0 Jodi furnishes us with an aesthetic example that resists the contemporary cultural trend toward the imperceptibility of the techniques used for organising contemporary data. Rather than using the graphic interface to obscure the underlying operations of computation, Jodi’s work insists on using visual elements to foreground the complex historical, social and economic factors that lie embedded within contemporary “user-friendly” interfaces.
¶ 56 Leave a comment on paragraph 56 0 Relational data aesthetics after the 1990s
¶ 57 Leave a comment on paragraph 57 0 Web design and use have now moved toward less visible engagement — certainly for the everyday user — with the underlying architecture and flow of data through its various nodes and mechanisms. As Olia Lialina has argued brilliantly, Web 2.0 is built upon an aesthetics of templates, which obfuscates the relations between play and work, user and knowledge corporation. It’s the search engines, the blogs, the social media that provide an already scripted space for users to play around in and have a good time. The time for “serious play” with which net artists such as Jodi and Heath Bunting were especially engaged, has been designed out of the contemporary network:
¶ 58 Leave a comment on paragraph 58 0 Why does Google want us to feel like home on their pages? Not to bind us to themselves, that’s for sure – they don’t need that; they’ve already got us hooked. When they offer me to “feel at home”, they mean something different. They mean home as opposed to work. What they’re saying is “Relax, have fun. Play around while we work. We are professionals; you are amateurs.” (Lialina, 2007)
¶ 59 Leave a comment on paragraph 59 0 Web 2.0 is a phrase used to denote the many changes that have taken place in the online environment since online cultures, commerce and everyday users regrouped in the post-dot.com context. At the core of the concept of Web 2.0 is the understanding of the network as an expanded field of interaction, interrelation and semantic generation between users, online infrastructure and software (see O’Reilly, 2005). Aggregators are a common feature of the information landscape of Web 2.0 as they are: a) automated forms of operations previously carried out by human labour in the Web 1.0 environment; b) methods for dealing with the explosion of online information that followed the growth of blogs from around 2002 onward; and c) able to link and function easily in relation to the straight-to-web environment that has become the mainstay of contemporary online transaction. Hence they provide a veneer of immediacy.
¶ 60 Leave a comment on paragraph 60 0 Users deploying such aggregators are usually not aware of what the parameters are for extracting and determining the stream or “pattern” of information brought together. The processes of making the data meaningful — that is, what holds this data together in an aggregate is not immediately available to us. Automatic aggregation tends to perform operations that reduce the relations between data to commonalities rather than differences. This may be of crucial importance in the aggregation of news data where conflicting rather than similar perspectives about an item actually comprise what is meaningful about it. But techniques such as aggregation smooth out these differentials and present us instead with a flattened landscape of information. The sources, processes and contexts, which make information meaningful, are rendered imperceptible.
¶ 61 Leave a comment on paragraph 61 0 How have networked artistic practices emerged to respond to this terrain of the imperceptible conditions for the generation of data? This goes beyond some aesthetic analysis of artistic practice in the Web 2.0 context, in which the online environment is conceived as a platform rather than a “site” for net art (see O. Goriunova and A. Shulgin, 2006). Goriunova has also suggested that if we understand the network as platform, we might give ourselves the opportunity to build art platforms that are noncommerical. For her, art platforms — while built from the same technologies as commercial Web 2.0 components — resist the banality of Web 2.0 culture and remain somewhat autonomous:
¶ 62 Leave a comment on paragraph 62 0 The situation is different with art platforms. If platforms are increasingly corporately owned, art platforms tend to be run by enthusiasts. The developer of a platform can sell it, the moderator of an art platform can’t. An art platform’s moderator is the one who registered the domain name, collaborated on or supervised the technical development of the resource, invested, along with other moderators, significant amounts of time into “raising” a platform, deciding on almost every single aspect of its development. The moderator(s) and the users together create a cultural entity which is coherent, specific and, importantly, small-scale. Its subject is avant-garde and marginal. (Goriunova, 2007)
¶ 63 Leave a comment on paragraph 63 0 Whether this is the case or not, I want to suggest here that the approach of data undermining is not about re-purposing, as Goriunova suggests is possible for online aesthetic platforms. Instead it follows a kind of inverse engineering mindset. Here I am invoking the ongoing projects of the Bureau of Inverse Technology, an art-research collective that has, since the 1990s, been using off-the-shelf software and hardware re-engineered to encourage such objects and systems to produce knowledge perversely alternative to the purposes for which such objects and systems were originally built. In undertaking this inversion process, the original technical systems and products, can often be seen to have a stake in delimiting, especially, the generation of open knowledge(s) in the public domain. Their original engineering and the history of their product development frequently spring from or can be complicit with proprietorial and/or military research. To invert the engineering of such software/hardware is not simply to rediscover the technical principles that structure and allow a technical artifact to function (reverse engineering). It is also to turn these principles inside out in the hope that by doing so something different, indeed a different kind of knowledge production, might take place.
¶ 64 Leave a comment on paragraph 64 0 In their commentary on the direction data mining has taken since its emergence in the 1980s, the artist collective RYBN note that data mining began as a largely economic tool and method used by banks and large corporations. Its spread, then, into areas such as security and knowledge resources such as libraries and even ‘humanitarian missions’, signals a more general ‘economization’ of the social. Data mining might be seen as a way in which knowledge is literally mined – that is, turned into a raw material or natural resource – for cultural capital. RYBN also note that the translation of what is social into what is economic is then again translated into the digital via data mining. Both data mining’s widespread growth and its digital nature make it opaque and less ‘readable’, RYBN assert. Their series of works that come under the project Antidatamining (2006-8) are an attempt to aesthetically render this economization of the social by producing a media archaeology of the information flows of contemporary culture.
¶ 65 Leave a comment on paragraph 65 0 The project seeks to do two things: visualize the kinds of global imbalances that are often obscured by ‘pictures’ of contemporary culture produced via data visualization; and divert data mining away from its utilitarian goals and toward an analysis of what social consequences its uses produce or trigger. So, while the project suggests an “against”, an “anti”, its staying power is derived from its inverse engineering, its ability to get at and under the closed world of the data mine.[7]
¶ 66 Leave a comment on paragraph 66 0 Something that is emphasised by RYBN is the idea that Antidatamining is a research project that transversally links artists, economists, programmers, data visualization experts and so on. While the artist-programmer collaboration is already well established in new media art, what is interesting in the present context is that RYBN begins to see the need for artists and economists to collaborate in the context of a digital knowledge economy. The research flavour of the project is articulated in the website by documenting and displaying the processes and steps the project underwent. For example, RYBN includes their initial forays into data visualization using the open source business data mining tool Rapidminer. RYBN also conducts “antidatamining” workshops, which aim to provide participants with the means to use the internet as a database for revisualizing information flows and use open source software such as Pure Data. Extra-net connections can be used to revisualize or resonify internet data, which can then be reprocessed and fed back into the online environment.
¶ 67 Leave a comment on paragraph 67 0 The first application RYBN developed is titled IP-Spy and was visualised in 2006.
¶ 68 Leave a comment on paragraph 68 0 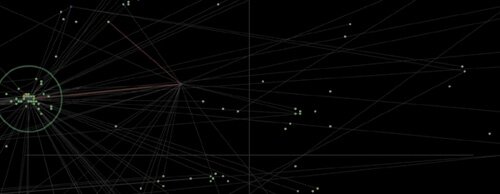
Screenshot of the IP-SPY Antidatamining project.[8]
¶ 69 Leave a comment on paragraph 69 0 Looking at it now, in 2009, it already feels as though the data aesthetic used tends to converge with the dominant link-node style of network. Its proximity to such a ubiquitous and dominating diagram means that we may have already moved past the impact such pieces once possessed. The application is a visualisation of the ‘activity’ of a network, where the RYBN url occupies the central node of that network. Other users or sites that have connected to the RYBN site are then mapped and distributed visually across a black space, reminiscent of global space. The visualisation provides a list of the IP, operating system, browser, country, city and previous site to which you were connected before you connected to the RYBN site. Such a visualisation promises, with irony, to bring all IP information under the surveillance of a central knowing node. Such a visualisation is perhaps interesting for RYBN; it lets them know who is connecting to their project and from where and under what network and computational conditions. It’s probably of interest to others who connect to RYBN as well as it gives a sense of the geo-spatial distribution of people/users aware of RYBN. It’s interesting to me, for example, because when I ran the application the visualisation clearly showed that no one in Australia and indeed very few people in the ‘global south’ know of RYBN.
¶ 70 Leave a comment on paragraph 70 0 But as an anti-datamining application it’s probably not achieving what the collective set out to do. To be fair the Antidatamining project has many other applications that uncover or perhaps simply recover the relations between visualization technologies and the economy. But one also has to ask: how achievable is the task of using data mining tools subversively, that is, to make them reveal their implicit assumptions and epistemic drives? Is it enough to simply reveal, for example, IP, browser data and so forth and then re-map this information? Part of the problem is the aesthetic of network cartography itself, which visually derives from the very operations of data mining. This aesthetic — its driving force — is what needs undoing. RYBN deliberately choose this aesthetic because, they say, it reveals the surveying forces implicit in this kind of data visualization tool. I’m not convinced that a revelation takes place over a compounding of the aesthetics of data visualization. The investigative direction of the project remains interesting, however, and it remains to be seen what collaborations between artists and economists might produce in the future.
¶ 71 Leave a comment on paragraph 71 0 Becoming-imperceptible in an age of perceptibility
¶ 72 Leave a comment on paragraph 72 0 Some of the networked art practices that data undermine also move beyond rendering visible the data management processes at stake in the arrangement of contemporary relational or networked data. Indeed, I want to suggest, along with Knouf in his statement on MAICgregator, that the move from creating specific net art sites to using the Firefox browser extension facility as an aesthetic strategy constitutes a radical shift in practice (Knouf, 2009). Not only does this mark an aesthetic change but, importantly, a social-ethical one. Extensions such as MAICgregator or Ad-Art developed by Steve Lambert produce novel spaces online that are both in and outside the norms of current Web 2.0 design and culture. What such projects demand is a socio-aesthetic domain for data in which users, techniques and flows are not appropriated by mindless automatism and in which the labour and work of all elements is not rendered imperceptible and, inevitably, irretrievable. But they do more, or at least provide the potential for something quite else: they facilitate alternative social-political spaces for knowledge generation rather than mere knowledge discovery (the goal of data mining).
¶ 73 Leave a comment on paragraph 73 0 One example of what I am talking about here is the ShiftSpace project. Once installed ShiftSpace — another piece using Firefox extension facilities — allows a layer of graphically displayed and designed text to sit over the top of any website.
¶ 74 Leave a comment on paragraph 74 0 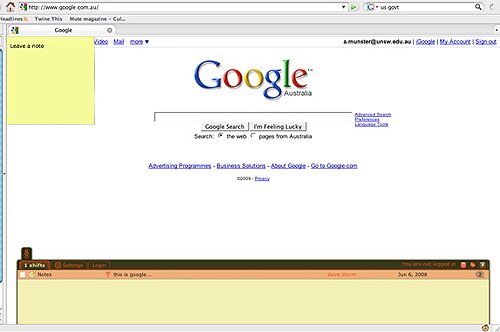
Screenshot of a Google page with the ShiftSpace plugin working showing one annotation as of April 2009
¶ 75 Leave a comment on paragraph 75 0 This text comprises annotations to the content or design of the site over which it sits that anyone with the plugin can write and share with others. Literally, the plugin shifts the space of online authoring, supplementing what has been privately designed and authorised by a site’s developer and owner with space visual and discursive space that is shared and produced by the ShiftSpace community. Begun in 2006 by Dan Phiffer and Mushon Zer-Aviv, not only has the ShiftSpace team grown to 10 people, but the ShiftSpace site also hosts an entire networked subculture of bloggers, plugin developers, commissions and so on. Strictly speaking, we are not talking about a data mining application or process, but I want to connect this project up with some of my previous discussion concerning the data undermining approach. This kind of metaweb production engages some of the same ethico-aesthetic impulses as the data undermining projects I have mentioned insofar as the effect of ShiftSpace is to move attention away from knowledge discovery toward a focus and effort upon knowledge generation or perhaps more aptly generative knowledge. It lets us get at the semantic content of the web in a way that opens that content up to new forms of authorship and, indeed, to re-authoring and a rediscovery of the aesthetics of textuality. ShiftSpace is to Web 2.0 what HTML was to the web of the 1990s. Moreover, with something like the kind of activities and frenzy of further plugins that extend ShiftSpace itself, knowledge production and meaning are redistributed to shared spaces that are not grid-locked by the aesthetics, ethics and politics of the network link-node form (as are social networking sites such as Facebook).
¶ 76 Leave a comment on paragraph 76 0 Here I want to go out a bit on a limb by suggesting that projects like ShiftSpace, Ad-Art and MAICgregator have a cosmic dimension to them. Not in a theological sense but in the sense that Gilles Deleuze and Feliz Guattari invoke when they talk about the cosmic as a pulsation toward making (a) world, “but becoming everybody/everything is another affair, one that brings into play the cosmos with its molecular components. Becoming everybody/everything is to world (faire monde) to make a world (faire du monde).” (1987: 307). In the current climate in which everything must be made into closed, determined, perceptible data — data which is authorised, data which is owned and data which already contains the known but just needs the right technologies to uncover knowledge — we need ways of generating new spaces or worlds that provide arenas for generating “data” differently. My reason for invoking the work of Deleuze and Guattari on the cosmic dimension of world-making in the context of an ethico-aesthetic approach to data aesthetics, is that they name this “worlding” a becoming-imperceptible. To unbecome ones proprietorial self — a web author, web user, database manager, developer even a “prosumer” and so on — and desire instead an undoing of these identificatory tags upon which knowledge production still relies, is to desire imperceptibility in an age of the perceptible. These agencies form the visible basis of knowledge production in the current digital economy, although, in fact, data is both generated and mined by much more complex assemblages of algorithms, patterns, connectivity and ownership (for example,the PageRank algorithm). Works such as Ad-Art and MAICgregator both reveal these complex social-machine worlds that produce ‘brands’ ‘sites’ and ‘knowledge’ and, simultaneously, allow us to see that making another world — or at least another set of social and knowledge spaces — out of the very data is also possible.
¶ 77 Leave a comment on paragraph 77 0 Becoming-imperceptible in an age of imperceptibility
¶ 78 Leave a comment on paragraph 78 0 The last area of contemporary networked aesthetic practice I want to explore folds into these questions of making and sharing worlds imperceptibility, and the relations to everyday online implementations. I am thinking here of the ubiquitous mining of information about user habits and “lifestyle” routinely conducted by all search engines.[9] The mainstay of the outcry against these automated profiling processes is that they violate users’ privacy and that they constitute a form of Big Brother style surveillance, which has shifted from state to corporation. But I want to suggest — and here I welcome the opportunity for much broader debate about the relations between knowledge economies and surveillance – that privacy is not the primary issue at stake here. We should take note of the response made by executives of the data mining software companies employed by search engines when the issue of privacy violation by search engine profiling is raised, “Search behavior is the closest thing we have to a window onto people’s intent,” said Jeff Marshall, a senior vice president of Starcom IP, an advertising agency.” (Hansell, 2006) Here the individual cannot in a sense be known and can only be approximated; the individual is, in fact, only secondary. What is primary is “search behavior”. And what is being “discovered” in this process of data mining is “behavior” or to put that into knowledge discovery speak: pattern. Data mining is not targeting a person, in other words, but a trend in a population, a “behavior” that can analyzed as a pattern. To cry out against these techniques in the name of privacy violation, then, is to miss the point, to fall short of the target. The individual is not at risk here, quite simply because the individual is not of importance. It’s the population as an averaged entity behaving in this or that way, which is at stake.
¶ 79 Leave a comment on paragraph 79 0 Data mining is a technique that belongs to knowledge economies modulated by the diffuse politics of biopower. Here I understand biopolitics in the broad sense, first invoked in the work of Michel Foucault and further elaborated especially by Maurizio Lazzarato. Biopower is marked by the historical shift, in western societies at least, from governing the individual to managing populations via techniques such as the statistical analysis and prediction of lifespan, habit, custom and so on (Foucault, 1980 and 1991; Lazzarato 2004). These techniques for managing populations now saturate “life” and can be found everywhere including the profiling of behavior in the online environment for the purposes of predicting future spending habits.
¶ 80 Leave a comment on paragraph 80 0 Here the aesthetics of data undermining becomes very sticky indeed. If we follow the line I have set up that connects Deleuze and Guattari’s becoming-imperceptible with an idea of undoing “the individual” and becoming “everybody”, it might initially appear that this is not dissimilar to the energies driving the generation of aggregated entities such as “lifestyles”. Perhaps becoming-imperceptible implies just this very fading of “the individual” and the massification of behavior in populations that is at the very heart of contemporary forms of power. Perhaps, too, we might find some leverage in covering over our online tracks and traces so that we cannot be made perceptible to the data mining activities of the search engine corporation.
¶ 81 Leave a comment on paragraph 81 0 These issues are at stake in a project such as TrackMeNot developed by Daniel Howe and Helen Nissenbaum. Again using the extension capacities of Firefox, TrackMeNot , once installed, sets off random search queries from a particular user’s IP issued to search engines themselves. The effect of this is to create much more information about a user’s search engine interactions than fits the actual searching habits or “pattern” of that user. As Howe and Nissenbaum poetically put it, “With TrackMeNot, actual web searches, lost in a cloud of false leads, are essentially hidden in plain view” (2006). Essentially, whatTrackMeNot generates is a low signal-to-noise ratio, which makes the automated profiling or extraction of clear data/signal about user behavior difficult. Data mining operates on the implicit assumption that users will leave traces in their data that can be tracked — that is, that provide clues to what their behavior might actually be. By aggregating enough of these traces in enough users, data mining promises to sift this tracking into a form that ultimately produces the pattern “behavior”.
¶ 82 Leave a comment on paragraph 82 0 Another project plunging into imperceptibility is Eduardo Navas’ Traceblog, which uses the TrackMeNot (TMN) application aesthetically. Using TMN to “cover” his own online browsing activities, Navas then logs the random queries generated by his TMN install and posts them to a blog via a remix aesthetic poetically undermined by foregrounding the noise that is the larger context of “pattern” or “behavior” in the online environment. What we get on Navas’ blog is not a window into the individual’s thoughts, habits or banalities but instead nothing but readable machine gibberish.
¶ 83 Leave a comment on paragraph 83 0 
Screenshot of Eduardo Navas’ Traceblog that has been running since 2008
¶ 84 Leave a comment on paragraph 84 0 What I find fascinating about Navas’ log is trying to follow through the random queries generated by his install of TMN, not for their patterns but for the associative semiosis they set off in a reader. It’s hard to get at these first off but following the “query” path eventually gets you there. The machine aesthetic traced out in Navas’ mundane activity of logging his daily online activities reminds me of the kind of random search results Google returned back in its early incarnations during the late 1990s and very early 2000s. For me, it is somehow comforting to know that the generation of a Borgesian universe is still possible if you push a search engine to frenetically do what it does best: search. But conjoining search with AI and statistical analysis, via data mining, is something altogether different. This is when biocontrol enters the arena and search is stratified into pattern and behavior predicated.
¶ 85 Leave a comment on paragraph 85 0 Navas engages with just such aesthetic stickiness, if we understand Traceblog in the context of a range of his aesthetic practices which critically engage with remix culture and networked forms such as social media. As he states, Traceblog shows his unwillingness to share information, while exposing how information can be taken from him. Traceblog also presents the surfing-logs in a way that is unappealing and hard to read by the online user, something blogs are usually designed to avoid. (2008)
¶ 86 Leave a comment on paragraph 86 0 This returns us to some of the ideas I raised at the very beginning of this chapter about force and about networks as forcefields. By remixing at the level of networked architectures — browser extensions with blogs — Navas forces together not simply forms but also the questions of sociality and individuation pervading this architecture. Here remix finds its strength in generating and investigating questions about the peculiar ways in which networking concatenates the public and private.
¶ 87 Leave a comment on paragraph 87 0 We cannot simply champion privacy and the individual against ubiquitous surveillance and the corporation. We need to look carefully at the technical forces at work in networks for they both modulate and generate power and potentialities. Perhaps, then, becoming imperceptible in an age of imperceptibility is not simply to retreat or withdraw into the issue of privacy. Rather it is to become noisy, as noisy as our machines. And in becoming noisy we might also generate different ways of listening, provided we remind ourselves that listening requires us to be in the midst of a world with others and other noisy things.
¶ 88 Leave a comment on paragraph 88 0 Once a corporate entity such as Google is raised upon the automation of search and then is fed by the technologies of knowledge discovery such as data mining, net critique and a critical generative networked aesthetics must also consider and play with such automatism. To data undermine, then, is to radically automate and to automate radically as a careful ethical and aesthetic gesture. The hope remains, even if this endeavour fails, of creating a more poetic pattern aimed at disaggregating behavior as a predictive and normative construction.
¶ 89 Leave a comment on paragraph 89 0 Endnotes
¶ 90 Leave a comment on paragraph 90 0 [1] See Alva. Noë, 2004, Action in Perception, Cambridge MA: MIT Press; Brian Massumi, 1999, “Strange Horizon: Buildings, Biograms and the Body Topologic”,
http://www.brianmassumi.com/textes/Strange%20Horizon.pdf; also available in Brian Massumi, 2002, Parables for the Virtual: Movement, Affect, Sensation, Durham: Duke University Press; Erin Manning, 2009, Relationscapes: Movement, Art, Philosophy, Cambridge MA: MIT Press.
¶ 91 Leave a comment on paragraph 91 0 [2] Source Nicholas Knouf 2009, MAICgregator Seenshots http://maicgregator.org/static/images/MAICgregatorScreenshotDoD.png, image used under the Copyleft, with restrictions license granted at http://maicgregator.org/license.
¶ 92 Leave a comment on paragraph 92 0 [3] For a good description of how neural nets and decision trees are used in data mining, see Henry Edelstein, (2005) Introduction to Data Mining and Knowledge Discovery, Third Edition, Potomac, MD: Two Crows Corporation, 11–17. For a critical analysis of the development and history of AI and machine learning,see John Johnston, (2008) The Allure of Machinic Life, Cambridge, MA: MIT Press, 287–336.
¶ 93 Leave a comment on paragraph 93 0 [4] See, for example, Albert-László-Barabási, (2002) Linked: The New Science of Networks, New York: Basic Books.
¶ 94 Leave a comment on paragraph 94 0 [5] These images are network visualisations taken from the following source (which is reproducible under an unrestricted CC license, provided author and source attribution is noted): source: T.C. Freeman et al, (2007), “Construction, Visualisation, and Clustering of Transcription Networks from Microarray Expression Data”, PLoS Computational Biology, October; 3(10), http://www.pubmedcentral.nih.gov/articlerender.fcgi?pmid=17967053.
¶ 95 Leave a comment on paragraph 95 0 [6] For an example of one of the texts from the 1990s that tries to come to terms with an analysis of data mining as a knowledge discovery method revealing pattern in data, see Usama Fayyad, Gregory Piatetsky-Shapiro and Padhraic Smyth (1996) “From Data Mining to Knowledge Discovery in Databases”, AI Magazine, Fall: 37–54.
¶ 96 Leave a comment on paragraph 96 0 [7] The phrase “closed world” is borrowed from the book by Paul Edwards, The Closed World, Cambridge, Mass.: MIT Press, 1996, For Edwards, the phase is intimately tied to the military research of the post-WWII period that enabled the development of the digital computer. The closed world of digital computing is a vector that has driven a line of development in which the computer becomes a machine that only “sees” or “understands” input (the environment/what is exterior to it), in terms of its own parameters. We can understand data mining as part of this closed world line of computational development: the goal of data mining is to discover what is already in the data, for example. Data, in other words, discovering its own parameters.
¶ 97 Leave a comment on paragraph 97 0 [8] See the antidatamining website under IP-SPY MAPlink, http://antidatamining.net/.
¶ 98 Leave a comment on paragraph 98 0 [9] See the article by Saul Hansell August 15 2006, “Marketers Trace Paths Users Leave on Internet”, The New York Times, http://query.nytimes.com/gst/fullpage.html?res=9C0DEFD9173EF936A2575BC0A9609C8B63&sec=&spon.
¶ 99 Leave a comment on paragraph 99 0 References
¶ 100 Leave a comment on paragraph 100 0 T. Adorno, (1997) Aesthetic Theory trans. R. Hullot-Kentor, Minneapolis: University of Minnesota Press, 1997.
¶ 101 Leave a comment on paragraph 101 0 W. Benjamin (1992) “The Work of Art in the Age of Mechanical Reproduction”, Illuminations, H. Zohn trans. London: Fontana, 211-244.
¶ 102 Leave a comment on paragraph 102 0 V. Campinelli (2007) “Interview with Vito Campanelli about Web Aesthetics”, Geert Lovink, nettime, http://www.nettime.org/Lists-Archives/nettime-l-0705/msg00012.html (accessed April 24, 2009).
¶ 103 Leave a comment on paragraph 103 0 G. Deleuze and F. Guattari (1987) A Thousand Plateaus, B. Massumi trans. London: Althone Press.
¶ 104 Leave a comment on paragraph 104 0 A. Dix, J. Finlay, G. Abowd and R. Beale (1998), Human-Computer Interaction (Second Edition), London: Prentice-Hall Europe.
¶ 105 Leave a comment on paragraph 105 0 M. Dodge and R. Kitchen (2000) Mapping Cyberspace, London: Routledge.
¶ 106 Leave a comment on paragraph 106 0 H. Edelstein, (2005) Introduction to Data Mining and Knowledge Discovery, Third Edition, Potomac, MD: Two Crows Corporation.
¶ 107 Leave a comment on paragraph 107 0 U. Fayyad, G. Piatetsky-Shapiro and P. Smyth (1996) “From Data Mining to Knowledge Discovery in Databases”, AI Magazine, Fall: 37–54.
¶ 108 Leave a comment on paragraph 108 0 M. Foucault (1980) ‘The Politics of Health in the 18th Century’, in C. Gordon, ed., Power/Knowledge: Selected Interviews and Other Writings, New York: Pantheon Books.
¶ 109 Leave a comment on paragraph 109 0 M. Foucault (1991) ‘Governmentality’, The Foucault Effect: Studies in Governmentality, G. Burchell, C. Gordon and P. Miller, eds. Chicago: The University of Chicago Press.
¶ 110 Leave a comment on paragraph 110 0 J. Goodwin(2005) “Inside Able Danger – The Secret Birth, Extraordinary Life and Untimely Death of a U.S. Military Intelligence Program” September, reposted on 9/11 Citizens Watch http://911citizenswatch.org/?p=673.
¶ 111 Leave a comment on paragraph 111 0 S. Hansell (August 15 2006), “Marketers Trace Paths Users Leave on Internet”, New York Times, http://query.nytimes.com/gst/fullpage.html?res=9C0DEFD9173EF936A2575BC0A9609C8B63&sec=&spon=.
¶ 112 Leave a comment on paragraph 112 0 N. K. Hayles (1990) Chaos Bound, Ithaca: Cornell University Press.
¶ 113 Leave a comment on paragraph 113 0 D. Howe and H. Nissenbaum (2006 and ongoing) TrackMeNot website, http://mrl.nyu.edu/~dhowe/TrackMeNot/.
¶ 114 Leave a comment on paragraph 114 0 O. Goriunova and A. Shulgin, (2006) “From Art on Networks to Art on Platforms”, Curating Immateriality: On the Work of the Curator in the Age of Network Systems, J. Krysa, ed. New York: Autonomedia.
¶ 115 Leave a comment on paragraph 115 0 O. Goriunova (2007), “Swarm Forms: On Platforms and Creativity”, Metamute, January 29, http://www.metamute.org/en/Swarm-Forms-On-Platforms-and-Creativity.
¶ 116 Leave a comment on paragraph 116 0 N. Knouf (2009) “Mining the Military-Academic-Industrial Complex in a Poetic-Serious Fashion”, MAICgregator website, http://maicgregator.org/statement.
¶ 117 Leave a comment on paragraph 117 0 M. Lazzarato, (1996) “Immaterial Labour.” Radical Thought in Italy: A Potential Politics, M. Hardt, l and P. Virno, eds, Minneapolis: University of Minnesota Press, 133-147.
¶ 118 Leave a comment on paragraph 118 0 M. Lazzarato “From Biopower to Biopolitics” Pli: The Warwick Journal of Philsophy vol.13: Foucault: Madness/Sexuality/Biopolitics, available online at: http://www.goldsmiths.ac.uk/csisp/papers/lazzarato_biopolitics.pdf.
¶ 119 Leave a comment on paragraph 119 0 O. Liailina (2007) “Vernacular Web 2.0″, New Network Theory conference, Institute of Network Cultures, University of Amsterdam, June 28–30. Also available at: http://www.contemporary-home-computing.org/vernacular-web-2/.
¶ 120 Leave a comment on paragraph 120 0 E. Navas (2008) “About Traceblog” http://navasse.net/traceblog/about.html.
¶ 121 Leave a comment on paragraph 121 0 T. O’Reilly, (2005) “What Is Web 2.0: Design Patterns and Business Models for the Next Generation of Software”, O’Reilly weblog, http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.html?CMP=&ATT=2432.
Very interesting reflection, I’m taking many cues from it.
Thanks for the quote, I just have to remark that my family name is: Campanelli.
Best,
V.
Sorry for the mispelling – will fix in the text! And please leave some actual cues or direct me toward any links you have that might take up some more of these questions about aesthetics
why are there no comments on this rich and inspired text? an effect of nonvisualization? probably a sign of post-austere time, and lack of time/s and yet, one wonders, in this open forum, why it has not attracted all kinds of feed back, questions, elaborations? is it the form of the text (dense essay, not much breathing room between paragraph, is it perhaps possible to ask whether such writing, inviting collaboration, needs to be modeled on a different kind of contact improvisational form, aware of gravity, weight, shifts, balances imbalances, stillnesses (which are never still) and movement opening, to let the others in, how do you so this in address/speech, in text, in novel, in essay, in scholarly book, in diary, in poem, where do these textual forms (even in electronic writing with visuals and videos) open the space to move in an dwell a while? i am not a networked text person nor write blogs or comment much on blogs if ever, so also am not quite aware of more leasured visibilities to mine, or undermine. i don’t follow the poetics of electronic writing (and the kind of things I remember K. Hayles lecture about a few years back, thos eliterary sites virtually were closed of course to all intervention – they seemed austere all right,
Amazing essay, Anna. It’s inspired me to restart work on some of my interface layering experiments. I’d be absolutely thrilled if you’d check my latest. You can find it here: http://www.contexture.in. Still very rough…
I’m curious about how/when the interfaces you mention in your essay will start to make their way into the everyday user’s browser. Their is a great deal of power in understanding the data/information underlying the web, but it is hidden behind our overwhelming dependence on a select few resources for finding information. Beyond making new pieces/tools which question information ownership and authority, what is the role of the artist/creator in educating the public that other avenues do exist?
Hi Alex,
thanks for your comments. I am going to check out your site in the next few days and after I’ve had a look at that maybe I will have some suggestions back for your provocations. The questions about ho artistic interventions enter mainstream culture are challenging…I need to have agood think about these!
Alex – I am wondering how contexture works? ie what is it doing to create the links/tags it selects – keyword searches? I think it looks great but I’m not sure what kind of information, beyond the visual, you were hoping to unfold or in a sense ‘mine’ as a result of peole installing the contexture plugin…do the colours code in a particular way ie is there a significance to them in terms of categories and so on.
In terms of when I think these kinds of strategies will become mainstream – who’s to say? At the moment the web is still pretty much caught in ‘search’ mode. Things that spread are still about ‘how to locate’. Probably one of the most successful of these as a kind of ‘alternative’ to centralised Web 2.0 cultures is the pirate bay, which is appartently in the top 100 of all websites used. And yet all it is is a simple index to help you locate ‘free’ (ie bit torrent) downloads.
I think the kind of plugins you and others I have written about are working with is a different level of networking, which has to do with reflection and reflexivity rather than seach. We could even say its kind of second order web! Unfortunately the direction of much networking is toward realtime, in which reflection is just about impossible!
Let me know what you think about these ideas…anna
[...] I have chosen to exploit the “proximity of relations,” which Anna Munster (2001; 2008) writes about in relations to networked art, yet the challenge I foresee will be the back and forth [...]
Google analytics, a now popular user-friendly datamining program that offers visualization keys such as maps, line graphs, and pie charts, is the very future that this project may have influenced.
The surfacing of Google Analytics is not only datamining made ‘friendly,’ the existence of GA is also the product of cultural mining, “high culture” mined for –> popular culture.
That creativity in the digital world becomes a commodity for e-giants is another level of frustration, esp. when the intent of the creativity is to react against the corporate.
Hi Anna,
my book on web aesthetics is just out (INC of Amsterdam). I would like to send you a copy, can you provide me a postal address?
Best,
V.
P.S.: Probably not the right place for such a request… sorry.
[...] http://munster.networkedbook.org/data-undermining-the-work-of-networked-art-in-an-age-of-imperceptib… [...]
[...] http://munster.networkedbook.org/data-undermining-the-work-of-networked-art-in-an-age-of-imperceptib… LikeBe the first to like this post. [...]
[...] Munster, Anna Marie. “Data undermining: the work of networked art in an age of imperceptibility” Networked: A networked book about networked art. Eds. Green JA; Hankwitz M; Mancuso M; Navas E; Thorington H. Turbulence.org. Jan. 2009. Web [...]